
The Problem:
Job boards are optimized for volume, not relevance.
As a UX/UI designer, I was scrolling through hundreds of roles, most irrelevant, outdated, or misaligned with my experience. The signal-to-noise ratio was low, and the time cost was high.
What I needed wasn’t more jobs. I needed the right jobs, aligned with my level, domain, and goals.

The Idea:
Build an AI-powered agent that:
Scans multiple job sources automatically
Filters roles based on relevance (title + experience)
Ranks opportunities by match quality
Explains why each role is a good fit
Delivers results proactively (no manual searching)
Not a job board. Not a dashboard.
System Design:
System Overview

The Agent (Backend Logic)
Fetches jobs from selected sources
Filters based on title and experience
Scores and ranks opportunities
Generates reasoning for each match
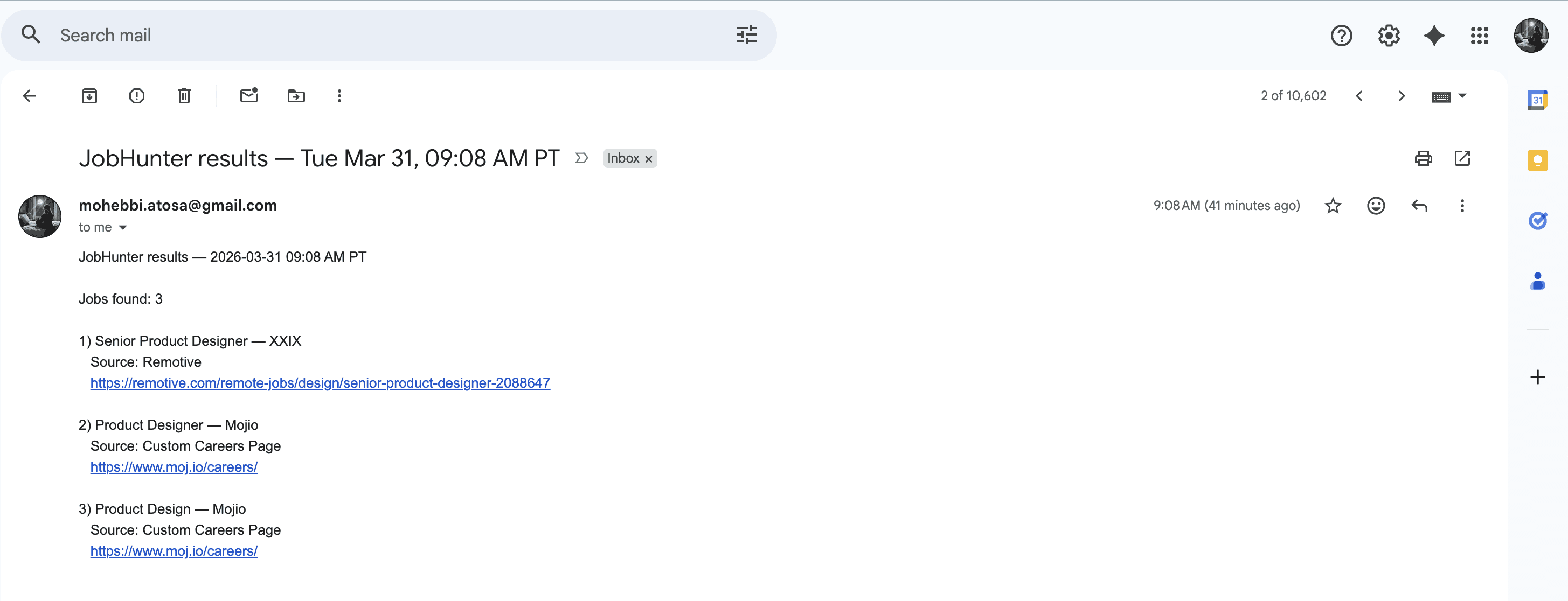
Sends curated results via email
The Interface (Decision Layer)
Displays ranked opportunities
Highlights the best match
Explains “why this matches you”
Helps users quickly decide where to focus
Together, they shift job search from browsing → decision-making.
The Process:
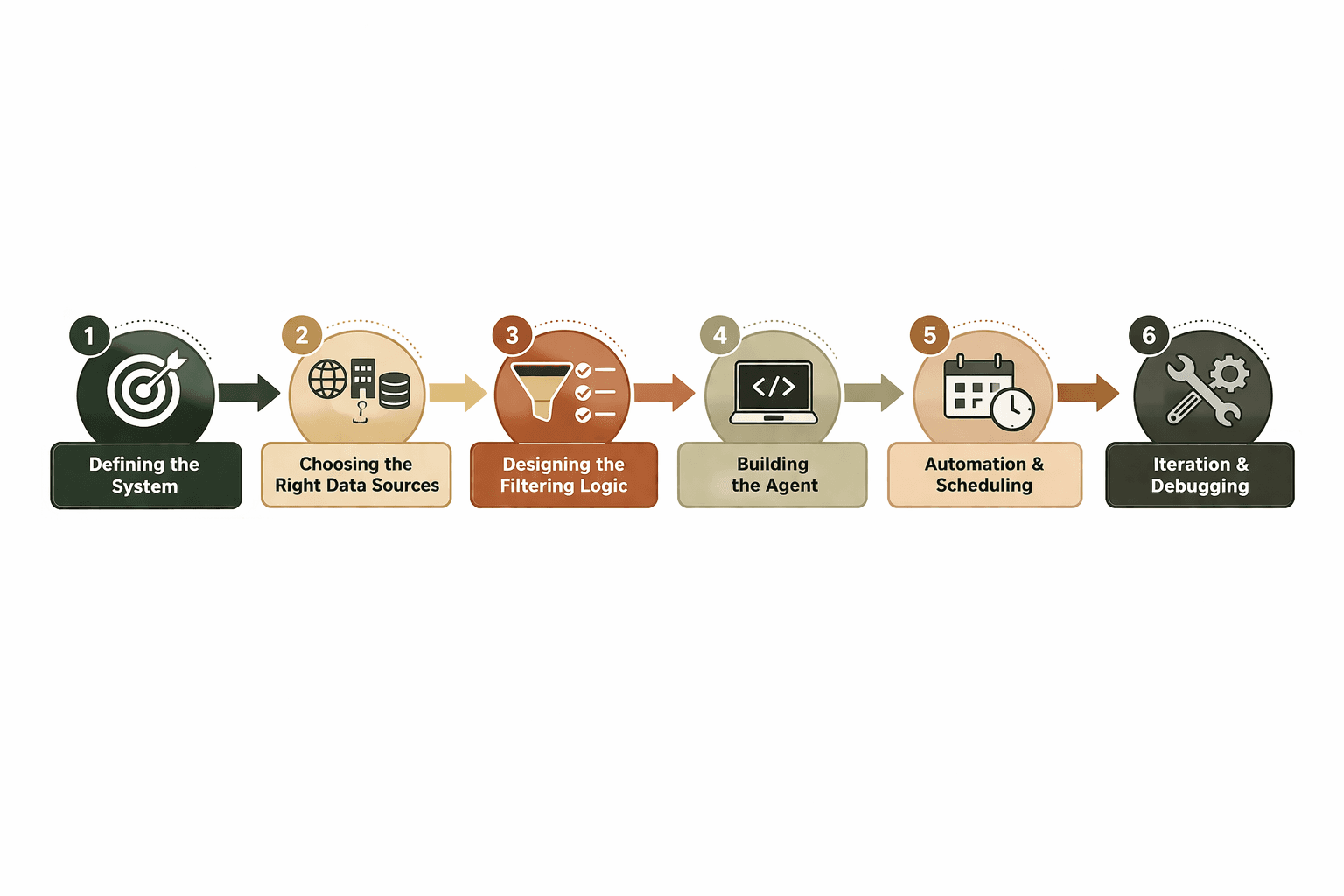
Defining the System
Before touching implementation, I defined what this agent needed to do well. It had to be push-based, not pull-based:
Pull jobs from reliable sources
Filter specifically for product/UX design roles
Prioritize early-to-mid career opportunities (1–5 years of experience)
Run automatically without manual input
Deliver results in a simple, digestible format
I also defined what this was not:
Not a job board
Not a dashboard
Choosing the Right Data Sources
The biggest decision was not technical, it was strategic. Most job boards are aggregators, which means:
Duplicate listings
Outdated roles
Low relevance
Instead of relying on generic platforms, I prioritized:
Remotive API for remote roles
Company career pages (targeted startups in Vancouver, Canada, and the US)
ATS systems like Greenhouse/Lever (future expansion)
This shift was critical. It turned the agent from a job scraper into a high-signal opportunity filter.
Designing the Filtering Logic
Building the Agent
Automation and Scheduling
The agent runs using GitHub Actions. Key decisions:
Runs twice daily
Uses a state file to prevent duplicate sends
Includes safeguards to avoid unnecessary runs
Iteration and Debugging
The Result:

A fully automated job discovery system that:
Runs twice daily without manual input
Filters roles based on title and experience
Prioritizes relevant product design opportunities
Reduces time spent searching while increasing quality of results
Instead of checking job boards, the right roles come to me.
What I'd Improve Next:
Introduce real-time personalization (user profile input)
Improve scoring using LLM-based reasoning
Expand data sources with structured APIs
Turn the system into a shareable produc